温馨提示:这篇文章已超过1243天没有更新,请注意相关的内容是否还可用!
为什么要设置网站 robots.txt
robots.txt 是一项国际建议,允许或限制搜索机器人收集网站和网页。作为参考,截至 2022 年 3 月,IETF正在进行标准化工作。
robots.txt 文件应始终位于您网站的根目录中,并且应以纯文本文件形式写入,以符合机器人排除标准。Naver Search Robot遵守robots.txt中写的规则,如果站点根目录下没有robots.txt文件,则认为可以收集所有内容。
有时,一些不完整的搜索机器人,包括为特定目的开发的网络爬虫,可能不遵守 robots.txt 中的规则。因此,对于不应该对外暴露的内容,包括个人信息,您必须通过登录功能或使用其他屏蔽方法对其进行保护。
robots.txt 位置
robots.txt 文件必须位于站点的根目录中,并且必须可作为文本文件 (text/plain) 访问。
示例)http://www.example.com/robots.txt
根据HTTP响应码处理
Naver搜索机器人访问网站robots.txt时,请提供正常的2xx响应码。搜索机器人根据HTTP 响应代码进行如下操作。
| 响应码组 | 解释 | |
|---|---|---|
| 2xx | 成功的 | 解释和使用符合机器人排除标准的规则。如果 robots.txt 作为 HTML 文档返回,它可能被解释为没有 robots.txt(全部允许),即使其中有有效的规则。因此,建议将其编写为遵循机器人排除规则的纯文本文件(text/plain)。 |
| 3xx | 重定向 | HTTP 重定向最多允许 5 次,如果发生更多重定向,则在停止后解释为“全部允许”。不解释通过 HTML 和 JavaScript 进行的重定向。 |
| 4xx | 客户端错误 | 解释为“全部允许”。 |
| 5xx | 服务器错误 | 它被解释为“全部禁止”。但是,如果有以前正确收集的 robots.txt 规则,则可能会暂时使用它。 |
robots.txt 规则示例
robots.txt 文件中写入的规则仅对相同主机、协议和端口号下的页面有效。http://www.example.com/robots.txt 的内容不适用于 http://example.com/ 和 https://example.com/。
代表性规则如下,请根据网站内容的性质进行更改。
它不允许收集其他搜索引擎机器人,只有 Naver Search Robot 设置为允许收集。
User-agent: *Disallow: /User-agent: YetiAllow: /
设置为允许收集所有搜索引擎机器人。
User-agent: *Allow: /
设置为只允许收集站点的根页面。
User-agent: *Disallow: /Allow: /$
不应允许访问搜索机器人的网页,例如管理页面和个人信息页面,应设置为禁止收集。下面的例子告诉 Naver 搜索机器人不应该收集 /private-image、/private-video 等。
User-agent: YetiDisallow: /private*/
通知所有搜索机器人不允许对网站的所有页面进行收集。不推荐使用此示例,因为它不会收集您网站上的任何页面。
User-agent: *Disallow: /
请允许收集 JavaScript 和 CSS 文件
有时,某些网站会将资源 URL(例如 JavaScript 和 CSS 文件)视为 robots.txt 规则中不允许的集合。在这种情况下,Naver 搜索机器人可能难以解读页面的关键区域。请允许搜索机器人收集包括 JavaScript 在内的资源文件。有关详细信息,请参阅JavaScript 搜索优化。
请允许收藏图标
如果某个网页的“出现在搜索结果中”的图标被 robots.txt 屏蔽了,我们可能会在不遵循 robots.txt 规则的情况下收集该图标作为例外。这是因为网站图标被视为暴露给搜索的网页中的基本组成资源。请使用与文档相同的 robots.txt 规则设置要搜索的文档的内部组件(css、javascript、图像..)。有关网站图标的更多信息,请参阅网站图标标记指南。
指定站点地图.xml
您可以通过将sitemap.xml的位置写入 robots.txt 来帮助搜索机器人更好地收集您网站的内容,其中包含您网站上的页面列表。
User-agent: *Allow: /Sitemap: http://www.example.com/sitemap.xml
使用站长平台的 robots.txt 工具
您可以使用网站管理员工具提供的 robots.txt 工具更轻松地管理您网站的 robots.txt 文件,它提供以下两个功能。
1.收集并验证robots.txt
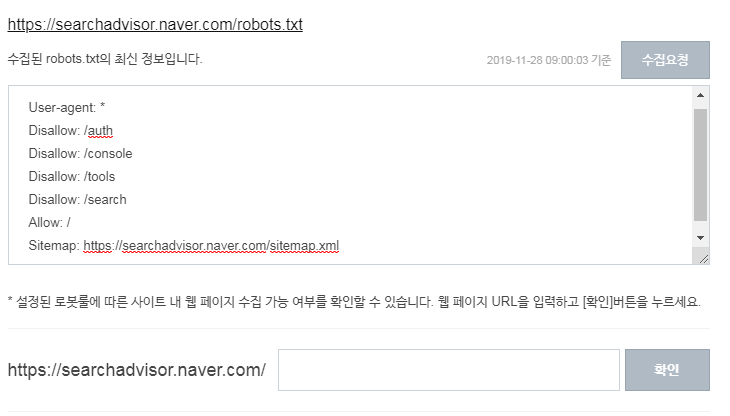
如果您想在编辑站点根目录中的 robots.txt 文件后快速通知搜索机器人,请单击请求收集。
您可以根据设置的机器人规则测试是否可以收集网页。
2.robots.txt的简单创建

您可以简单地创建一个 robots.txt 文件并下载它。将下载的robots.txt文件上传到网站根目录后,执行上述步骤1中的采集请求,Naver Search Robot立即可以识别。




还没有评论,来说两句吧...